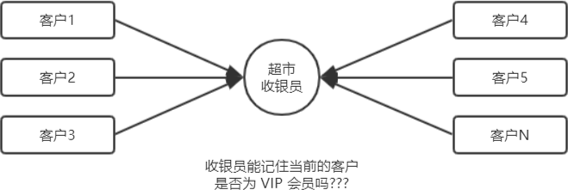
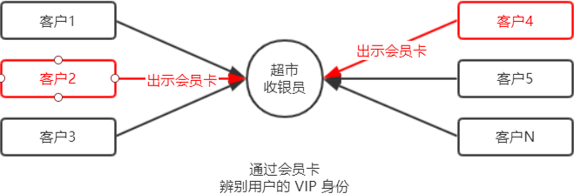
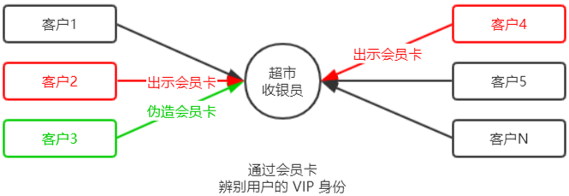
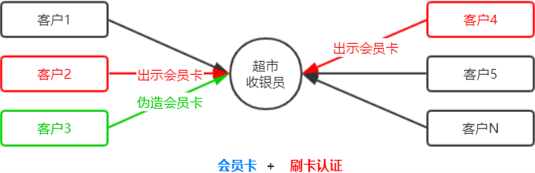
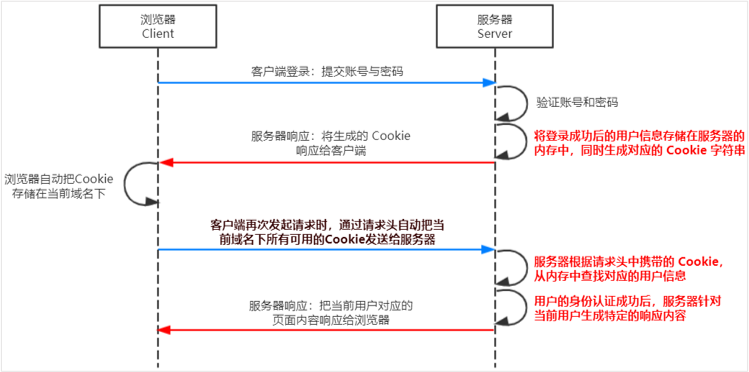
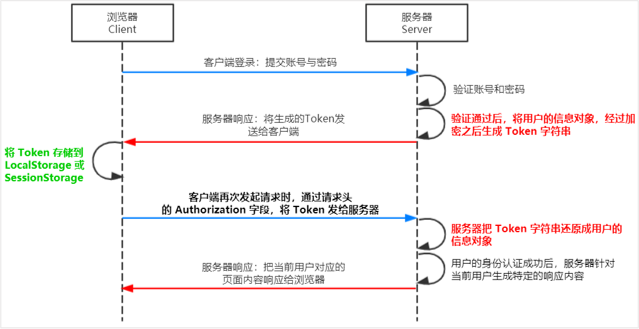
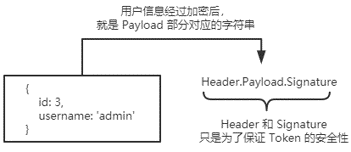
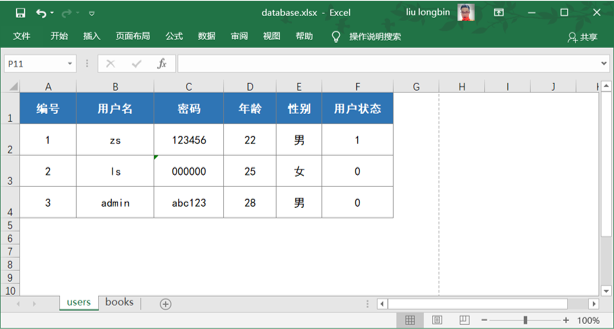
身份认证(Authentication)又称“身份验证”、“鉴权”,是指通过一定的手段,完成对用户身份的确认。 日常生活中的身份认证随处可见,例如:高铁的验票乘车,手机的密码或指纹解锁,支付宝或微信的支付密码等。 在 Web 开发中,也涉及到用户身份的认证,例如:各大网站的手机验证码登录、邮箱密码登录、二维码登录等。
额外需要掌握的 4 种 SQL 语法: where 条件、and 和 or 运算符、order by 排序、count(*) 函数 注意:SQL 语句中的关键字对大小写不敏感。
查询数据(select)
1 2 3 4 5 6
-- 从 from指定的[表中],查询出[所有的]数据.*表示[所有列] select * from 表名称 select * from users -- 从from指定的[表中],查询出指定 列名称(字段)的数据 select 列名称 from 表名称 select username from users
插入数据(insert into)
1 2
insert into table_name (列1,列2,...) values (值1,值2,...) insert into users (username,password) values ('tony stark','000000')
更新数据(update)
1 2 3 4 5 6
-- 语法解读: -- 1.用 update 指定要更新哪个表中的数据 -- 2.用 set 指定列对应的新值 -- 3.用 where 指定更新的条件 update 表名称 set 列名称 = 新值 where 列名称 = 新值 update users set password='888888' where id = 7
删除数据(delete)
1 2 3
-- 从指定的表中,根据 where 条件,删除对应的数据行 delete from 表名称 where 列名称 = 值 delete from users where id = 4
SQL 的 WHERE 子句
WHERE 子句用于限定选择的标准。在 SELECT、UPDATE、DELETE 语句中,皆可使用 WHERE 子句来限定选择的标准。
SQL 的 AND 和 OR 运算符
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。 AND 表示必须同时满足多个条件,相当于 JavaScript 中的 && 运算符,例如 if (a !== 10 && a !== 20) OR 表示只要满足任意一个条件即可,相当于 JavaScript 中的 || 运算符,例如 if(a !== 10 || a !== 20)
1 2
select * from users where status=0 and id<3 select * from users where status=1 or username='zs'
SQL 的 ORDER BY 子句
ORDER BY 语句用于根据指定的列对结果集进行排序。 ORDER BY 语句默认按照升序对记录进行排序。 如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
1 2 3 4
-- order by 默认进行升序排序 -- 其中,asc关键字代表着升序 select * from users order by status; select * from users order by status asc;
1 2
-- desc关键字代表着降序 select * from users order by id desc
多重排序 对 users 表中的数据,先按照 status 字段进行降序排序,再按照 username 的字母顺序,进行升序排序,示例如下:
1
select * from users order by status desc,username asc
SQL的COUNT(*)函数
COUNT(*) 函数用于返回查询结果的总数据条数,语法格式如下:
1 2 3 4
select count(*) from 表名称 select count(*) from users where status=0 -- 使用AS 为列设置别名 select count(*) as total from users where status=0
在项目中操作mysql
在项目中操作数据库的步骤
1.安装操作 MySQL 数据库的第三方模块(mysql) 2.通过 mysql 模块连接到 MySQL 数据库 3.通过 mysql 模块执行 SQL 语句
1.安装mysql模块
1
npm i mysql
2.配置mysql模块 在使用 mysql 模块操作 MySQL 数据库之前,必须先对 mysql 模块进行必要的配置,主要的配置步骤如下:
1 2 3 4 5 6 7 8 9
// 1. 导入mysql 模块 const mysql = require('mysql'); // 2. 建立与 mysql 数据库的连接 const db = mysql.createPool({ host: '127.0.0.1', // 数据库的 IP 地址 user: 'root', // 登录数据的账号 password: 'admin123', // 登录数据库的密码 database: 'my_db_01'// 指定要操作哪个数据库 });